One of the most significant use cases for the Encodian Power Automate connector is to perform OCR (Optical Character Recognition) on PDF files. It allows those documents to become discoverable to search engines such as SharePoint. And you can also begin to work with the data contained within the documents. But what do you do if you already have large SharePoint repositories of PDF files that don’t have a text layer? Or you might have a text layer, but you’re not sure!
One option is to use the OCR, a PDF Document action provided by the Encodian Power Automate connector. A flow can be created to retrieve documents from a library, apply the text layer, and update the existing file. Or you could store it in an alternative location. This is a perfectly acceptable solution but can become cost-prohibitive for bulk OCR requirements. Power Automate is suitable for day-to-day OCR automation, but how do you handle the bulk OCR on large SharePoint repositories?
Introducing Encodian Indxr!
The Encodian Indxr application can be installed and run on a Windows desktop (or server). Simple configuration can automatically detect OCR PDF documents held in a SharePoint document library or a specific folder. Processed documents can be added to the source or an alternative SharePoint destination, and further options are available to copy metadata, copy permissions, force OCR, overwrite the source file and filename prefixes:
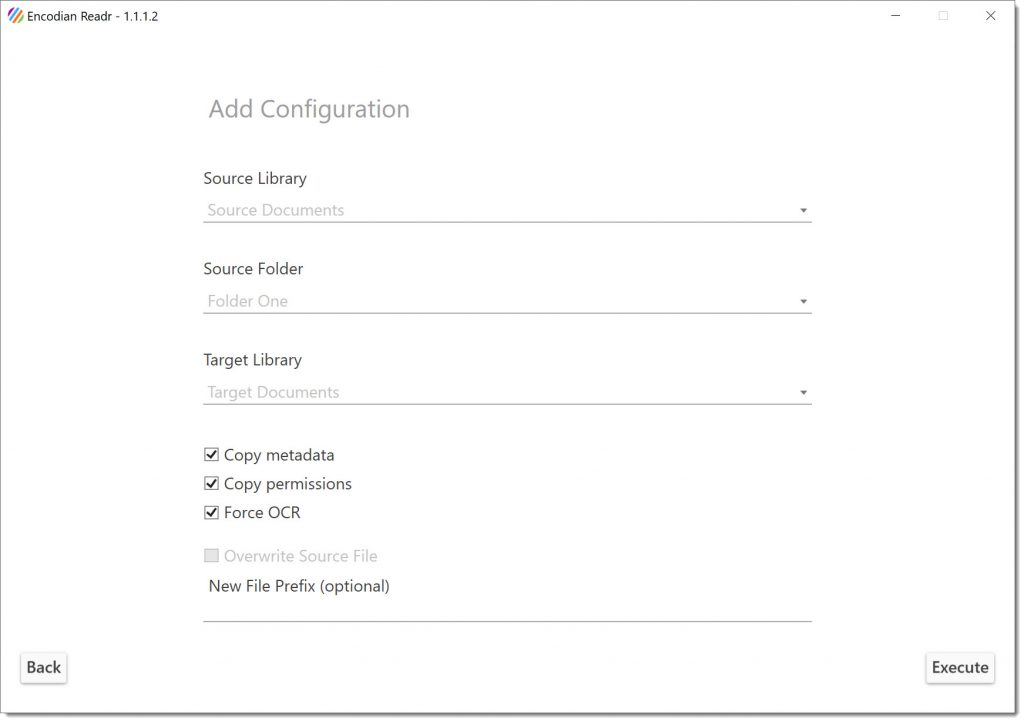
By default Encodian Indxr will check for the presence of a text layer on the PDF before processing the document, and it will be skipped if a text layer is present. However, by selecting the ‘Force OCR’ option, a new text layer would always be created through OCR.
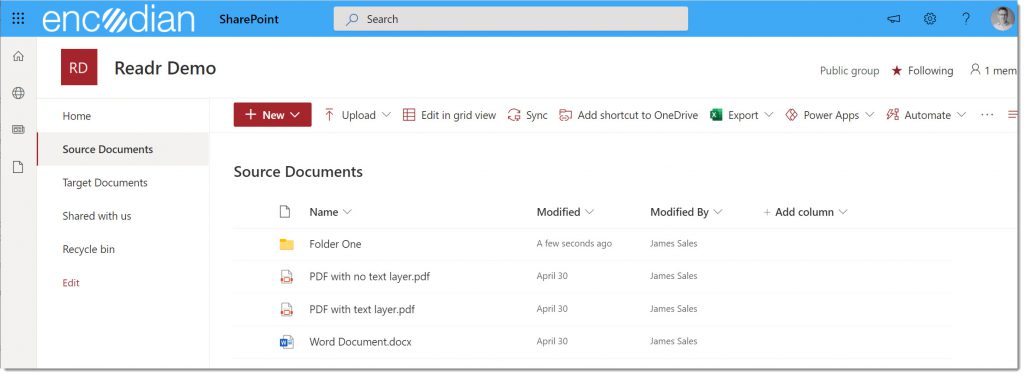
As a quick example, Consider a SharePoint document library containing three files: one Word document and two PDFs. One PDF file has a text layer already, and one does not. There is also another folder that contains the duplicate three files (so six files in total):
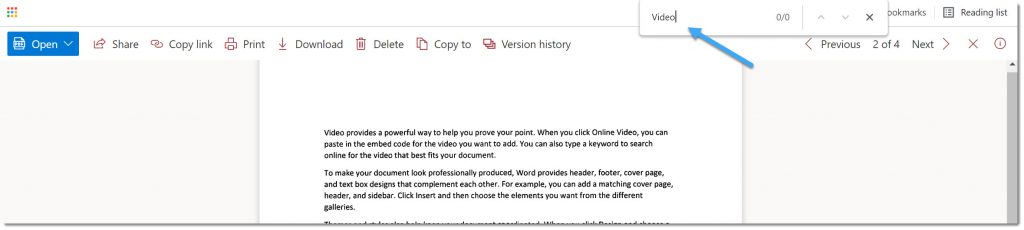
If I open the PDF with no text layer in the browser and search for some text, there is no result:
The exact search against the PDF with a text layer yields results:

For this example, the objective is to OCR required PDF documents and store the updated (OCR’d) files in a new SharePoint location.
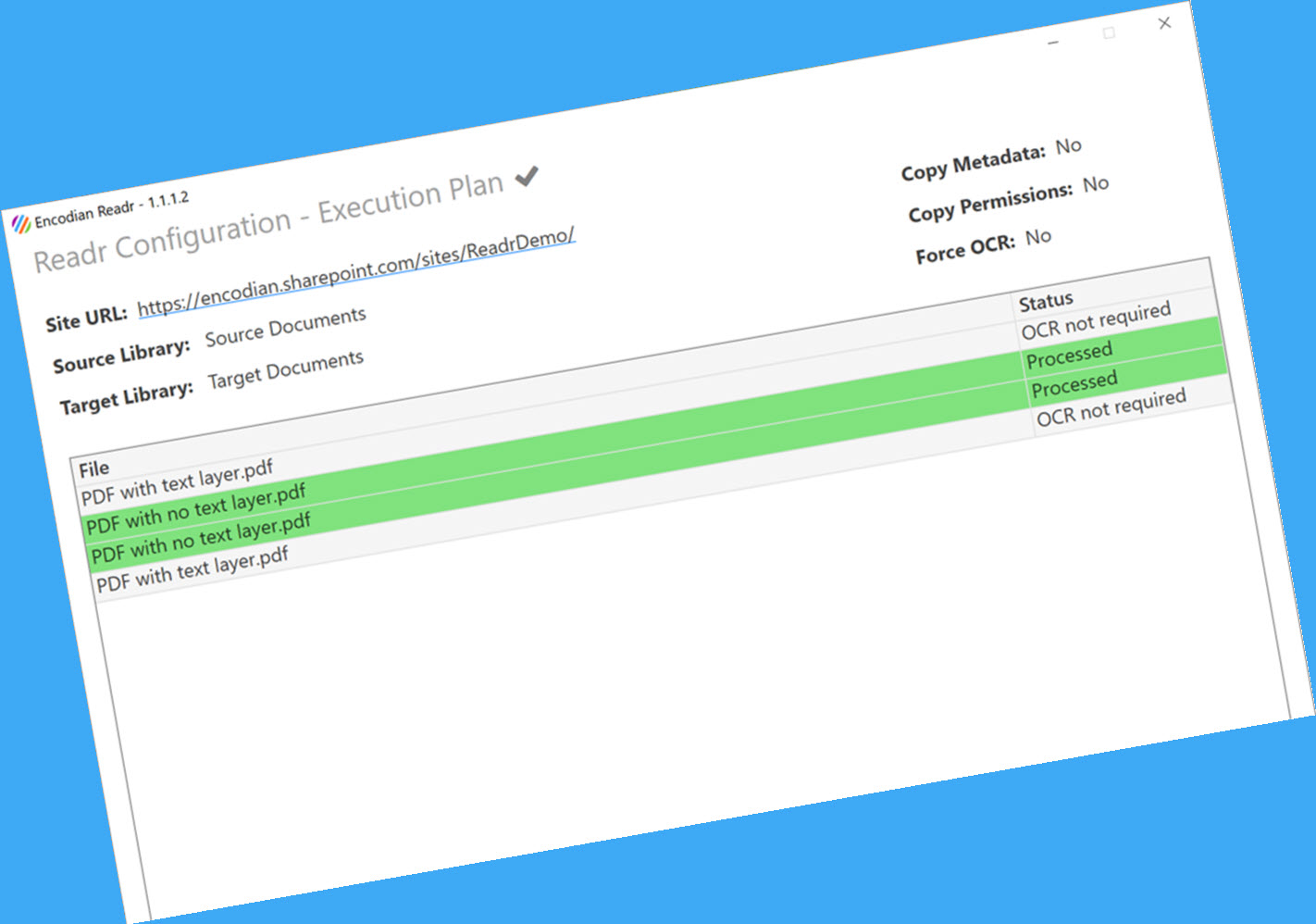
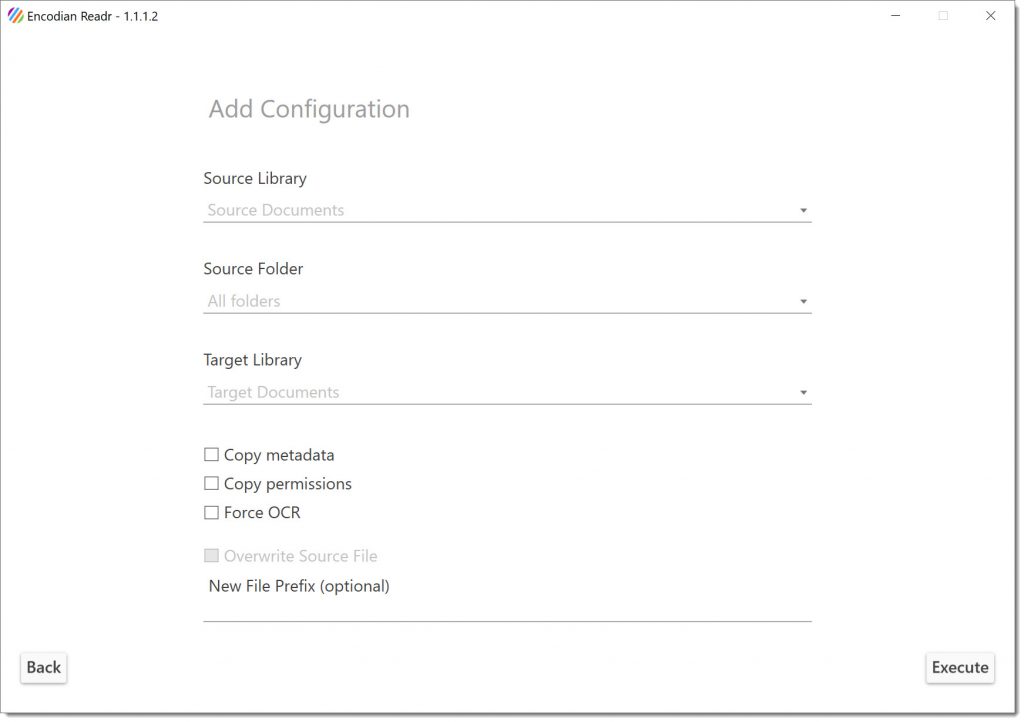
A new configuration can be created that specifies the source and target SharePoint libraries; we aren’t going to copy metadata or permissions, nor will we force OCR. The aim is to just OCR those PDFs that don’t currently have a text layer and copy the result to the “Target Documents” library:
When executed, the Indxr application processes all PDFs within the source library, identifying and performing OCR as required. Indxr provides a visual cue by highlighting in green those documents that have been OCR’d. In the unlikely event that an issue should occur during processing, the file would be highlighted red:
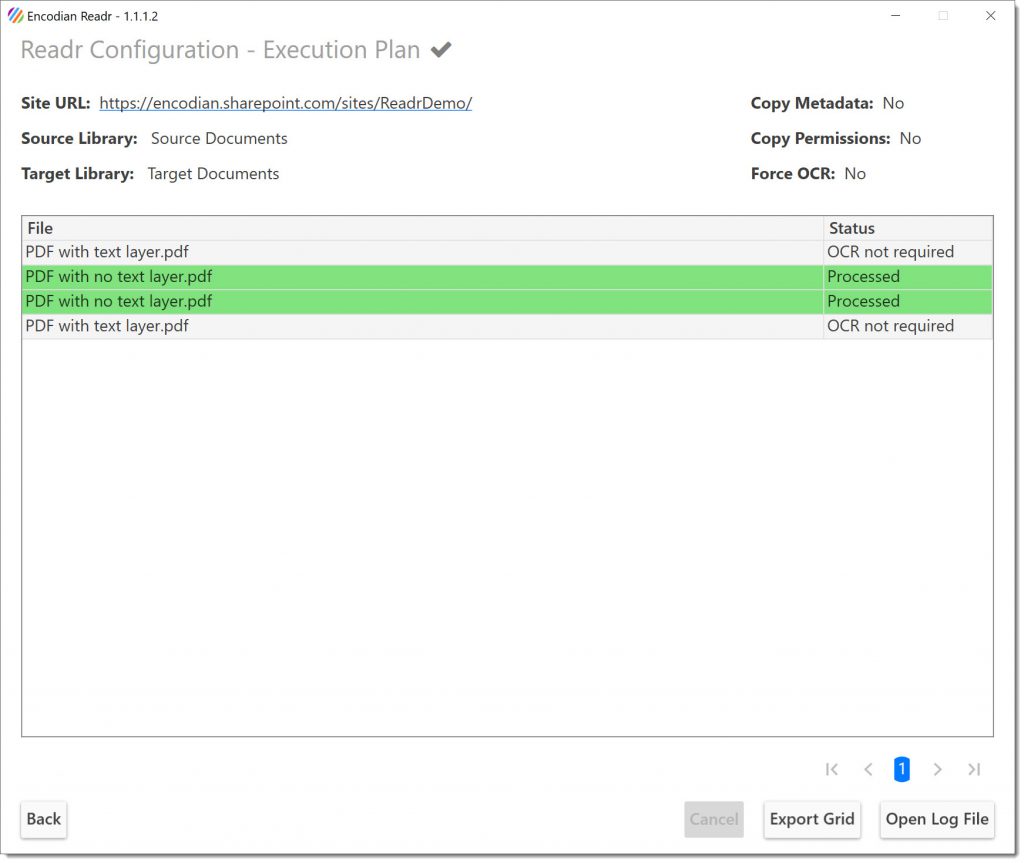
During and after execution, the user can examine the log files and export the grid output for further analysis.
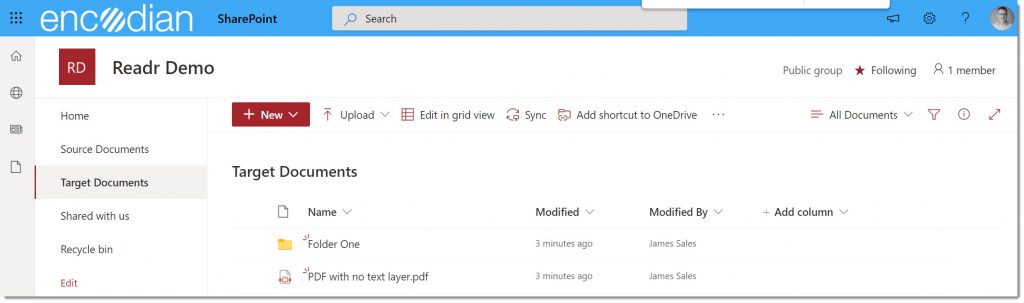
Let’s examine the target library. We can see that the file ‘PDF with no text layer.pdf’ has been created. So has the folder that also contained another copy of this file:
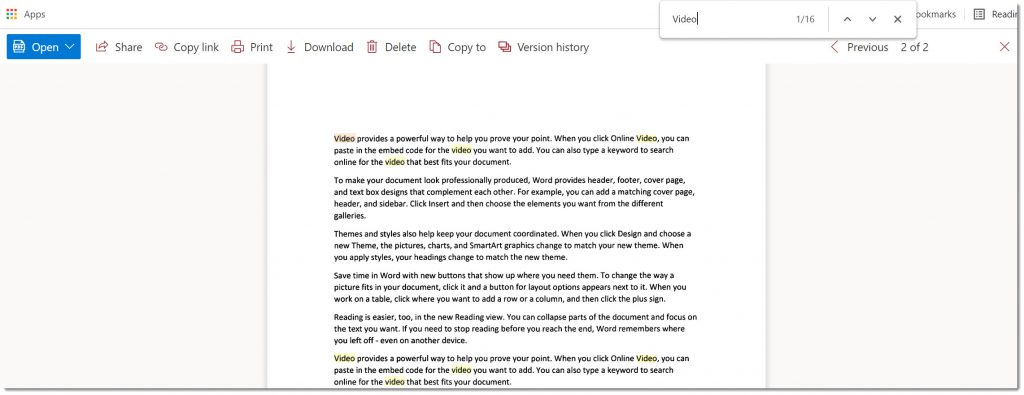
If we examine the file, we can now search for text within the body of the document:
Indxr provides the perfect solution for performing bulk OCR of large repositories of PDFs within SharePoint Online document libraries.
We know by this point, you’re ready to OCR PDF files in SharePoint! So if you would like to arrange a demonstration, please email hello@encodian.com, and a team member will be in touch.

