In addition to the Encodian Split PDF action, we have just released the Split PDF by Text action which allows you to search for text (or use a regular expression) within a PDF document and perform split actions based on the page location of the text matches found.
This post will outline how to use Power Automate to split a PDF document by text using both a free text search value and a regular expression.
Split a PDF Document on Separator Sheet
For this example, the document used is a scanned PDF document containing multiple documents where separator sheets were inserted to indicate the end and start of a new document, each separator sheet contains the text ‘Page Separator‘, which we’ll use as our search criteria within the action.
This example flow simply uses a ‘Manual Trigger‘ but of course your Flow could be triggered by any action supported by Power Automate (New file created, updated, email received, etc.)
1. Create a new Flow using the ‘Instant — from blank‘ option
2. Enter a name for the Flow, select the ‘Manually trigger a flow‘ trigger action and click ‘Create‘

3. Add a SharePoint ‘Get file content‘ action
3.a. Site Address: Enter the location of the SharePoint site where the target file is stored
3.b. File Identifier: Select the source PDF Document

4. Add an Encodian ‘Split PDF by Text action
4.a. Filename: Enter the name of the source file
NOTE: The ‘Filename‘ value will be used to post-fix the name of the resulting documents, for example, source.pdf would return files with names ‘0001_source.pdf, 0002_source.pdf‘ etc.
4.b. File Content: Select the ‘File Content‘ property from the SharePoint ‘Get file content‘ action

4.c. Split Value: Enter the text phrase to locate
4.d. Is Expression: Set to ‘No‘
4.e. Split Configuration: Select ‘AllInstances’, this instructs the split engine to create a new document for every page which contains the ‘Split Value’
4.f. Split Action: Select ‘Remove’, this instructs the split engine not to include the page containing the ‘Split Value’ in the resulting documents.

Please visit the Split PDF by Text action documentation to discover more details on the ‘Split Configuration‘ and ‘Split Action‘ options.
5. Add a ‘Create file‘ SharePoint action
5.a. Site Address: Set to the value of the SharePoint site which contains the target document library
5.b. Folder Path: Set to the value of the target SharePoint folder
5.c. File Name: Select the ‘Documents Filename‘ property from the Split PDF by Text action
Upon selecting the ‘Documents Filename‘ property, Power Automate will automatically wrap the action within a ‘Apply to each‘ loop. This is because the Split PDF by Text action returns an array of documents.
5.d. File Content: Select the ‘Documents File Content‘ property from the Split PDF by Text action

6. The completed flow should follow this construct:

Post execution the flow should have split the PDF document provided as the per the configuration:

And the resulting files added to the configured SharePoint location:

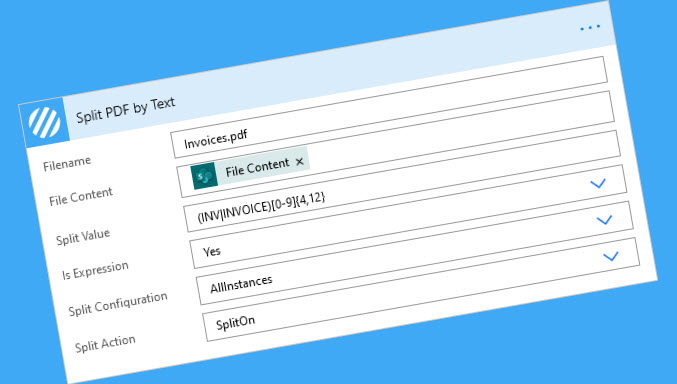
Split a PDF Document using a Regular Expression
Please refer to the previous section regarding how to configure your flow, we are simply going to change the configuration of the Encodian ‘Split PDF by Text action (Step 4) to locate text using a regular expression.
To enable regular expression search we simply need to change the ‘Is Expression‘ property value to ‘Yes‘

The regular expression should be added to the ‘Split Value‘ property:

In this example the PDF document contained multiple invoices and the regular expression is searching for any text instances which begin with either ‘INV’ or ‘INVOICE’ and end with four to twelve numbers (0 to 9).
For reference the regular expression is: (INV|INVOICE)[0-9]{4,12}
The engine detected four invoices creating four documents from the document provided:

Example Document:

Finally…
Hopefully, this post outlines succinctly how to use the Split PDF by Text action to perform PDF document splitting actions within your Power Automate flows, please share any feedback or comments – all are welcome!

