Zonally extracting data sounds daunting, but it doesn’t have to be!
Many of us, over time, will have worked on projects/solutions where there is a requirement to extract data from documents and do something with that data. A typical scenario could be processing a scanned document or documents sent from an external source, which is commonplace in ‘Invoice Processing’ scenarios.
This step-by-step guide details how to configure a Microsoft Power Automate Flow to extract data from a PDF document and add the data as metadata to the current document.
Scenario
The finance department generates invoices using a third-party application which uploads the documents to a SharePoint library for storage. To enable invoice reporting, tracking and related activities, we have a requirement to extract data from each invoice and add metadata to the document. The SharePoint library is configured as follows:

Guide
1. Create a new Flow using the ‘Automated — from blank‘ option

2. Enter a name for the Flow, select the SharePoint ‘When a file is created in a folder‘ trigger, and click ‘Create.‘

3. Configure the ‘When a file is created in a folder ‘ trigger action setting the ‘Site Address’ and ‘Folder Id’ fields to the location where documents will be added.

NOTE: For this demo, documents will already be in PDF format. However, should there be a need to extract data from a Word document, PowerPoint file, CAD drawing etc., convert to PDF first using the Encodian ‘Convert to PDF‘ action
4. Add the Encodian ‘Extract Text Regions‘ action
4.b. Filename: Select the ‘File name‘ property from the ‘ When a file is created in a folder‘ action

4.c. File Content: Select the ‘File Content‘ property from the ‘ When a file is created in a folder‘ action

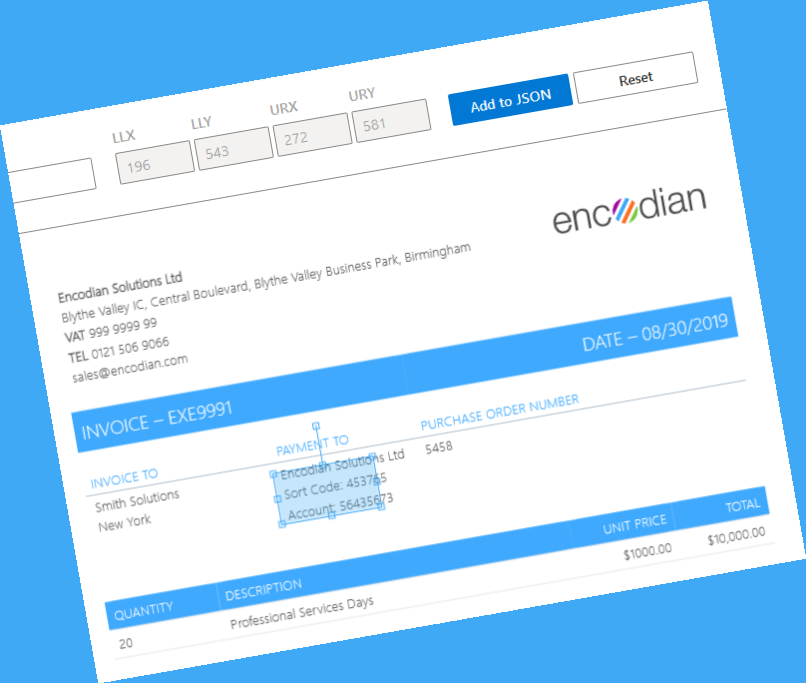
To progress the configuration of the ‘Extract Text Regions‘ action, we need to provide coordinates of the data on the source document, i.e. Zonal extraction.
So how do we get the coordinates? Easy! Use the ‘Text Region Generator‘ utility in the Encodian administration portal.
4.d. Upload a sample PDF document

4.e. Drag and move the area selector to the target area of the document

4.f. Define a name for the region and then click ‘Add to JSON‘

4.g. Repeat this process for all target regions of the document.
4.h. Copy the generated JSON data into your clipboard

4.i. Go back to Microsoft Flow; On the ‘Extract Text Regions‘ action, click the ‘Switch to input entire array‘ icon

4.j. Copy and paste the JSON data obtained in step 4.h. into the ‘Text Regions‘ field

5. We now need to obtain a sample of the generated JSON data, enabling us to add additional actions to parse and use the returned JSON data.
5.a. Test the Flow using your preferred method. Click ‘Save & Test‘

5.b. For this example, I selected ‘I’ll perform the trigger action‘, which I invoked by manually uploading a PDF invoice document to the SharePoint library aligned to the configuration of the trigger action (step 3).
5.c. Once the Flow has been executed, open the ‘Extract Text Regions‘ action and copy the ‘Simple Text Region Results‘JSON returned.

NOTE: If you have submitted a large file, Flow may display the outputs differently, prompting you to download the output manually. See the example below:

You’ll need to manually download the payload and locate the ‘Simple Text Region Results‘ variable. You’ll also need to manually remove any escape characters ‘\’ using either a text/code editor or an online service.
If you require further guidance on how to Parse JSON data, please review the following post: Parsing JSON returned by Encodian Actions
6. Add a ‘Parse JSON‘ action
6.a. Content: Select the ‘Simple Text Region Results‘ property from the ‘ Extract Text Regions ‘ action
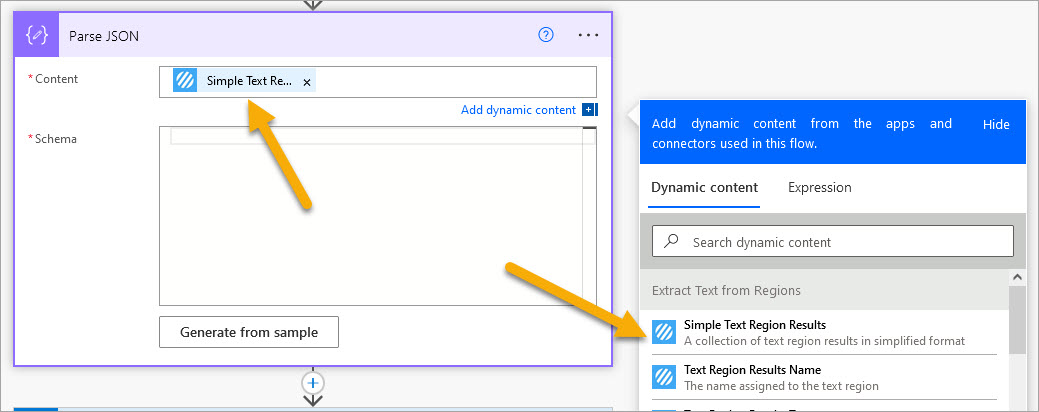
6.b. Click ‘Generate from sample.‘
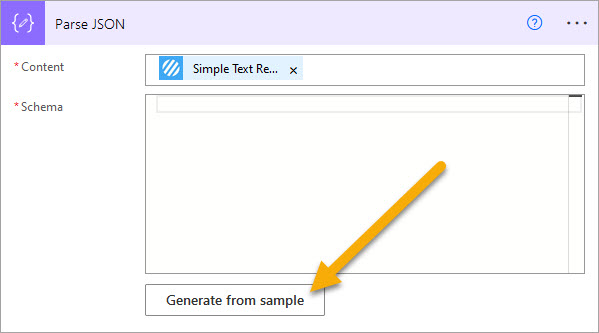
6.c. Paste the ‘Simple Text Region Results‘ obtained in step 5.c into the text-area control, and click ‘Done.‘

7. Add a ‘Get file metadata using path‘ action
7.a. Site Address: Set as per step 3.
7.b. File Path: Select the ‘File path‘ property from the ‘ When a file is created in a folder‘ action.

8. Add an ‘Update File Properties‘ action
8.a. Site Address: Set as per step 3.
8.b. Library Name: Set as per the library name contained within the ‘Folder Id‘ property of step 3.
8.c. Id: Select the ‘ItemId‘ property from the ‘Get file metadata using path‘ action

8.d. Map data from the ‘Parse JSON‘ action to the relevant fields

9. Test the Flow by using data from the previous run

10. Validate the flow run has successfully executed

11. Validate data has been extracted and added as document metadata correctly

While this example has focused on how to extract document data before setting SharePoint document metadata, once the data has been extracted, you can do anything with the data using the power of Microsoft Power Automate!
We hope you’ve found this guide to zonally extract data valuable! As ever, please share any feedback or comments. All are welcome!


9 Comments
Can we use this software to extract image OCR data from a PDF file? Is that possible?
Hi,
Yes, please refer to the OCR a PDF document action
HTH
Jay
hello, once i have my parse JSON Schema set up, can i use the data collected to auto fill selected PDF files with the same input criteria ?
Hi Jack,
Yes, please refer to the following post: Fill a PDF Form with Microsoft Power Automate
Cheers Jay
This is very nice solution! A viable alternative to using Forms Processing in AI Builder.
This is great. Works really well. Would you be able to then make the flow distinguish different purchase orders by supplier name and have a different data extraction regions for each supplier within the same folder?
Hi Dean,
Yes, but this is not an AI extraction based solution, you’ll need to extract data and build the regions manually and configure your flow to manage this. HTH
Is there a recommended solution within Encodian to extract data from a PDF that was originally an excel file where there are multiple rows for a given column?
Hi Jason, you can do this with the extract regions action by creating a region where data might appear… really you should look at Microsoft’s AI solutions for the Power Platform. HTH